
 保育與休閒部
保育與休閒部 保育。保護。享受。
保育與休閒部 




 目錄
目錄本節介紹 DCR-DNH 在收集現場資料和開發生態群落分類時所採用的程序。
資料收集
DCR-DNH 生態學家致力於使用標準實地採樣協議和數值數據分析方法來進行植物採樣、分析和分類的定量方法。這一重點與北美和歐洲的植物研究歷史以及美國植物分類的國家標準一致(Jennings et al.2009; 皮特等。2012)。定量數據明確識別共存植物種之間的豐富和生物質的差異。從已知標準大小的樣本單位收集的資料提供一致的基礎,用於比較不同的植物群,並促進使用者在不可能透過簡單的物種清單或從不定規模的區域收集的數據進行分享。生態社群組成和結構的模式取決於觀察的規模,並且指定特定比例的採樣協議可減少跨多個規模模遮蔽模式的可能性和取樣器偏差在確定是否記錄特定物種時。同樣地,數值分析方法提供了客觀的方法來產生和評估植物分類,並允許檢測否則可能不明顯的模式。收集和分析用於支持生態分類的定量數據,不應該被視為萬象,也不應該視為自己的目標。相反,它們作為進一步保護生物多樣性的工具很重要,但它們為此提供了一個關鍵的目標和科學背景。
Data collection follows standard protocols developed and refined by DCR-DNH over the past 25 years. The fundamental components of these protocols are consistent with sampling techniques employed by other state Natural Heritage programs a wide range of other users (e.g., Peet et al. 1998). For inventory purposes and most contract projects, data are collected from plots 400 m2 in forests and woodlands and 100 m2 in shrubland and herbaceous vegetation. On natural area preserves and other managed areas that require permanently marked plots for long-term monitoring, modular plots up to 1000 m2 that contain nested subplots are sampled more intensively to provide information about vegetation structure, composition, and species richness at multiple spatial scales. In all cases, within each plot all vascular plants present are recorded and the total individual cover of each taxon (defined as the vertical projection of all above-ground biomass) is estimated and assigned to one of nine cover classes representing a range of percentage values. Vegetation structure is assessed by estimating the cover of each woody species at six vertical (height) strata, and stem diameters are measured for all woody stems => 2.5 cm at breast height (1.4 m). A standard set of environmental data is collected, including elevation, aspect, degree of slope, coverage of different types of surface substrate, soil characteristics, and qualitative measures of soil moisture and hydrology. A soil sample is routinely collected from each plot in order to document soil chemistry. All sampling locations are recorded using a global positioning system (GPS). The sampling protocol can include photographic documentation and cursory examination of tree increment cores to deduce stand age and history. Click here for a copy of the DCR-DNH standard plot data collection field form and Instructions (requires the free Adobe reader).
數據分析與分類
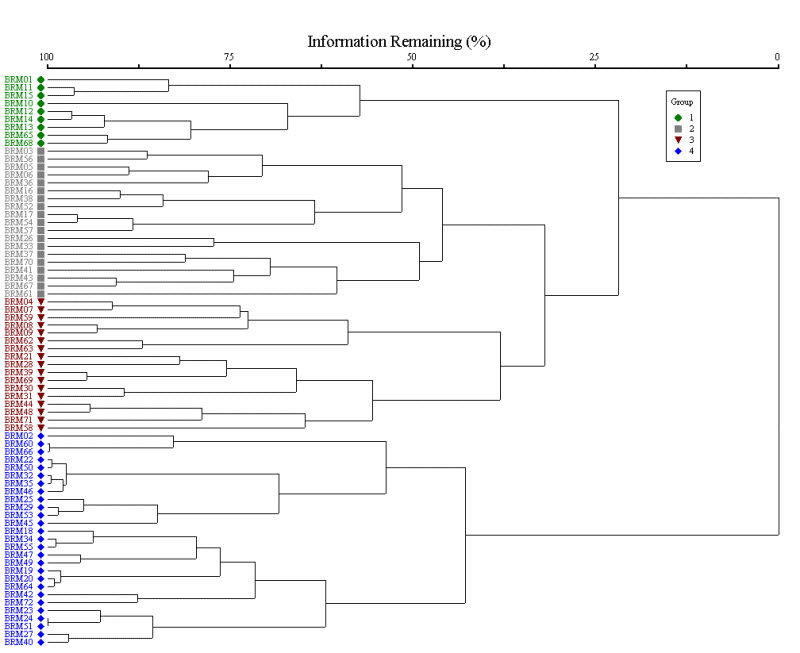
使用數值方法來生成分類,並且強調在弗吉尼亞州和地區範圍內的整個分佈範圍內的單位進行限制。DCR-DNH 生態學家秉承植被類型的識別應基於整體植物組成的原則,採用聚類分析進行分類。叢集分析是一種數值分類的方法,該方法可評估定量樣本的相似性,並通過互動式統計過程將最相似的樣本合併為叢集。植被生態學中使用了不同類型的聚類分析:DCR-DNH 生態學家使用凝聚層次聚類分析,從每個樣本在其自己的組開始,然後逐步將它們融合成更大的組。結果顯示為測距圖,這是一種類似樹狀圖形,描述逐漸融合群組的解析度。作為例,此測距圖顯示了 72-plot 數據集的叢集,以及可能代表植物類型的四個主要群組的識別。
隨後,進行定位,以評估分類,並確定那些與物種組成的變化最有關聯的環境梯度和地點條件。排序是一種多變量技術,根據組成的相似性和相對物種豐富性,將植物樣本相互相對排列。排序程序總結縮小座標系統中的多維數據,從而提取解釋資料中最多變化的軸。DCR-DNH 生態學家使用非公制多維度縮放(NMDS),這是基於間接漸層分析,在可能的範圍內最大化了樣本間不相似性和樣本間距離之間的排序(即非參數式)關聯性。順序分析的結果通過圖表描述,其中每個點代表一個繪圖,點之間的距離大致表示構成相似程度。測量環境變數與每個軸上的樣本座標之間的統計意義相關性可以繪製為向量,並覆蓋在圖表上。向量的方向表示通過座標空間的最大關聯方向,而向量線長度則由相關的強度決定。此圖表顯示用於說明叢集分析的相同資料集的二維排序。符號表示在標準圖中識別的四個群組,並繪製顯著的環境漸層。
叢集分析和定序都在 PC-ORD 中實現(版本 6;麥肯和梅夫福德 1999-2011)。確定潛在植物類型後,會計算幾個摘要統計數據,以評估該類型的一致性和獨特性,並幫助選擇名稱分類。物種特定的恆定值(指定給物種出現的植物類型的繪圖比例)、忠度(物種限制於特定類型的程度)和平均覆蓋範圍,可確定每種類型最具特性和主導性物種。
社群名稱
社群類型的命名類與 USNVC 採用的標準類似,該標準使用最多五種特徵物種的科學名稱。儘管它們無法用作詳細描述的完整代替代品,但是社區類型的名稱是為了促進兩種類型之間的區分,以及在現場上輕鬆識別它們。弗吉尼亞州名稱最多使用六種特徵物種。通常,物種按照重要性和結構位置的遞減順序列出(即,首先列出了多層物種,然後列出了底層物種,然後是草藥和低灌木)。用作名稱的物種具有很高的恆定性(通常是 > 60%,但如果特別是診斷的話,偶爾會是 > 50%)。同一層中的名義物種用虛線(-)分隔,而不同的層則用斜線 (/) 分隔。括號中列出的物種在類型中不太常數,但在本地重要。當兩種物種列在括號內時,這意味著一種或兩種在給定階段中可能很重要。正式社區類型名稱的末尾包括典型的生理學(例如森林、森林、灌木叢等)以及潮汐濕地社區的水文制度。普通名稱等效不是名稱物種的拉丁名稱的嚴格翻譯,而是通常指生態群組名稱,並包含組成或地理修改因子。作為例子,
海洋紫蘇尼亞-科德里亞-維爾吉尼卡-普爾西卡·普爾西卡塔潮汐草本植物
淡水潮濕沼澤(野米-混合花種)紅色龍蝦-美洲小龍-黑斑尾草-(白斑)/綠色斑紋-棕櫚樹脂-森林
中阿巴拉契亞基本滲漏沼澤

{kind=link}
{kind=link}